[4-1] Basic Machine Learning
1. AI, ML, DL의 개념
AI
AI(인공지능)는 컴퓨터를 통해 인간의 지적 능력을 구현하는 기술
인공지능은 크게 두 가지로 분류된다
- 강한 AI: 인간의 능력을 뛰어넘는 AI. 인간보다 더 뛰어난 지능을 가진 시스템
- 약한 AI: 특정 영역에서 도구로 사용하기 위해 설계된 AI(특정 작업만 잘하는 AI). 현재 우리가 일상에서 접하는 대부분의 AI가 이에 해당한다
ML
머신러닝(ML)은 컴퓨터가 인간처럼 스스로 학습하여 새로운 규칙을 발견하는 기술
인간이 일일이 규칙을 프로그래밍하지 않아도 데이터를 통해 스스로 학습하는 것이 핵심이다
DL
머신러닝의 한 종류로, 신경망(Neural Network) 사용
뇌를 본뜬 구조로, 층이 깊을수록 더 복잡한 문제를 잘 해결한다
예) 자율주행차, 음성 인식
2. 머신러닝의 개념과 과정
머신러닝은 알고리즘을 사용하여 데이터를 분석하고, 분석을 통해 학습한 다음, 학습한 내용을 바탕으로 판단이나 예측을 수행한다
머신러닝의 기본 과정:
- 빅데이터 입력
- 데이터 분석을 통한 모델 생성
- 생성된 모델을 사용하여 결정, 예측 수행

3. 딥러닝의 개념
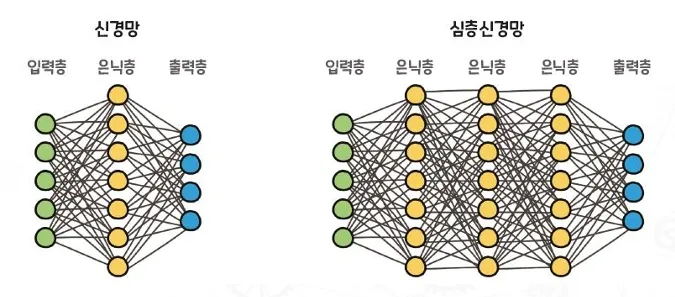
딥러닝(DL)은 여러 은닉층(hidden layer)을 가진 인공신경망(ANN; Artificial Neural Network)을 사용하여 머신러닝을 수행하는 기술

인공신경망은 상호 연결된 뉴런들의 네트워크로 구성된다
딥러닝에서 "Deep"은 연속적인 신경망의 층이 깊다는 것을 의미한다
신경망의 층이 깊어질수록 일반적으로 성능이 향상된다

4. ML과 DL의 차이점
1) 인간의 개입 (Human in the loop)
- 머신러닝: 데이터에 레이블을 지정하거나 데이터의 특징을 추출하는 등 인간의 개입이 일정 부분 필요
- 딥러닝: 인간의 개입 없이 스스로 학습함. 즉, 딥러닝은 더 자율적이다

2) 특성 추출 (Feature extraction)
- 머신러닝: 컴퓨터가 스스로 학습하기 위해서는 인간이 인식하는 데이터를 컴퓨터가 인식할 수 있는 데이터(벡터)로 변환해야 함. 이를 위해 각 데이터가 어떤 특성을 가지고 있는지 파악하고 데이터를 벡터로 변환하는 작업이 필요하다
- 딥러닝: 데이터의 특성을 신경망이 자동으로 추출함. 사람이 직접 특성을 정의하지 않아도 된다

3) 데이터 의존성(Data dependencies)
- 딥러닝: 주어진 문제를 해결하기 위한 중요한 특성을 직접 추출하기 때문에 충분한 데이터가 없으면 정확한 특성을 추출할 수 없다
= 딥러닝은 일반적으로 대량의 데이터가 필요하다. 데이터의 퀄리티와 양에 따라 딥러닝의 성능이 좌우됨 - 머신러닝: 상대적으로 적은 데이터로도 작동할 수 있음
충분한 데이터가 주어지면, 딥러닝은 인간이 인식하지 못하는 중요한 특성까지 식별할 만큼 뛰어난 성능을 발휘한다

4) 신경망 사용(Using neural network)
- 딥러닝: 심층신경망을 사용하여 입력 데이터에서 특성을 추출하고 결과(예측 또는 분류)를 스스로 도출한다. 심층신경망의 사용은 딥러닝의 특징
ML과 DL의 차이점

- 머신러닝의 하이퍼파라미터 튜닝: 튜닝할 수 있는 하드파라미터가 몇 개 없다
- 딥러닝의 데이터 양: 데이터가 적으면 바이어스, 가중치가 쏠릴 수 밖에 없다
- 머신러닝과 딥러닝의 정확도: 판별하기 힘든데(교차점이 존재하기 때문) 요즘은 데이터가 많기 때문에 그걸 기준으로 딥러닝의 정확도가 더 우수하다고 판단한다
- 딥러닝의 훈련시간: 해당되는 형태의 모든 뉴런에 반복 학습되기 때문에 오래 걸린다
5. 기본 프로그래밍의 한계
기본 프로그래밍은 예외처리의 연속이다
일반적인 프로그래밍에서는 모든 조건과 규칙을 미리 코딩해야 한다
하지만 복잡한 문제에서는 모든 경우의 수를 고려하기 어렵다
AI에도 decision tree라고 있긴 하다

머신러닝의 유용성
- 대량의 데이터와 많은 변수가 관련된 복잡한 작업에 매우 유용
- 기존의 규칙 기반 프로그램으로는 해결할 수 없는 복잡한 작업이나 문제를 해결할 수 있음
6. 머신러닝 훈련 방식
- 지도학습(Supervised learning): 분류와 회귀
- 비지도학습(Unsupervised learning): 군집화
- 강화학습(Reinforcement learning): 환경에서 취한 행동에 대한 보상을 통한 학습

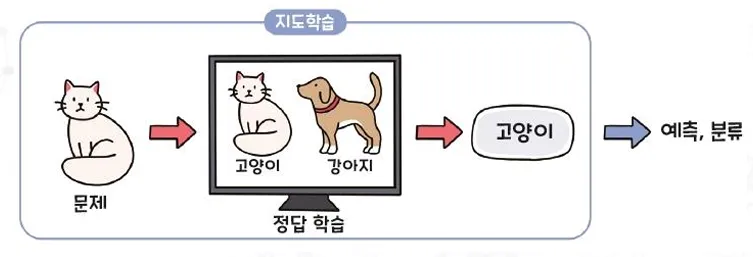
1) 지도학습(Supervised learning)
질문과 답변을 함께 학습하여 미지의 문제에 대한 정답을 예측하는 방법
- 예측(prediction)과 분류(classification)
2) 비지도학습(Unsupervised learning)
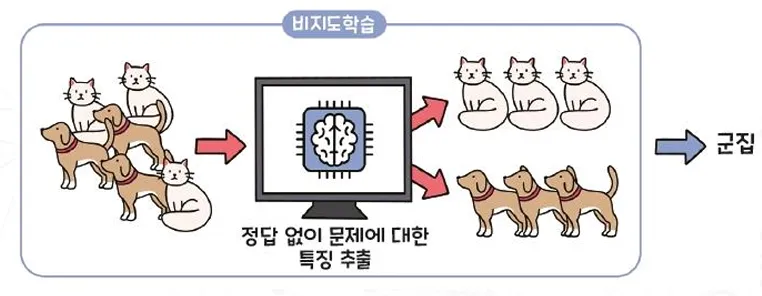
인간의 도움 없이 컴퓨터가 스스로 학습하는 형태
컴퓨터는 훈련 데이터를 사용하여 데이터 간의 규칙성을 찾는다
- 군집화(clustering)
지도학습과 비지도학습의 차이
지도학습은 입력 데이터(x)와 레이블(y) 사이의 관계를 식별
비지도학습은 x 자체의 관계를 식별
→ 가장 큰 차이점은 레이블(y)의 부재

3) 강화학습 (Reinforcement learning)
행동에 대한 보상(패널티, 리워드)을 받아 학습하는 방식
컴퓨터가 주어진 상태에서 최적의 행동을 선택하는 방법을 학습한다
보통 게임이나 로봇에 이용된다

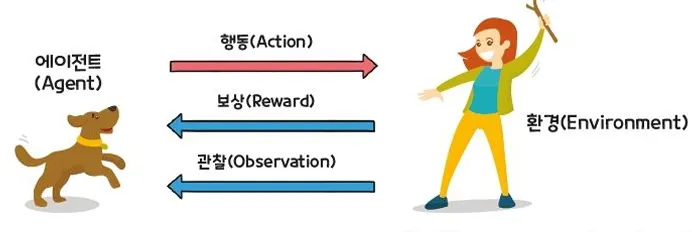
강화학습의 구성요소
- 에이전트(Agent): 주어진 문제 상황에서 행동하는 주체
- 상태(State): 현재 상황
- 행동(Action): 에이전트가 취할 수 있는 옵션
- 보상(Rewards): 에이전트가 행동을 취했을 때 따르는 이득
- 환경(Environment): 문제 자체
- 관찰(Observation): 에이전트가 수집한 정보
강화학습의 작동 방식
에이전트가 주어진 환경에서 선택한 행동에 따라 보상을 받고, 이를 통해 학습하는 과정
- 행동이 올바른 선택이면 보상을 받고, 잘못된 선택이면 벌을 받는다
- 강화학습은 에이전트가 상태를 관찰하고 더 높은 보상을 향해 행동(behavior)을 학습할 수 있게 한다
예) ChatGPT의 답안에 좋아요, 싫어요 피드백
이를 통해 사용자가 좋아하는 형태로 답안을 출력해준다
7. 분류(Classification) - 지도학습
레이블이 있는 데이터를 학습하고, 유사한 속성을 가진 데이터를 분류하는 기술
새로 입력된 데이터가 어떤 그룹에 속하는지 찾아내는 방법
주어진 데이터가 어떤 그룹(클래스)에 속하는지 판단하는 것이다
- 이진 분류(Binary classification): 데이터를 2개 그룹으로 분류 (OvO(Oner versus One))
- 다중 분류(Multiclass classification): 데이터를 3개 이상의 그룹으로 분류 (OvR(One versus Rest))

주요 분류 알고리즘:
- K-최근접 이웃(K-Nearest Neighbors)
- 서포트 벡터 머신(Support Vector Machine)
- 의사결정 트리(Decision Tree)
1) K -최근접 이웃(KNN) 알고리즘
새로운 데이터가 들어왔을 때, 기존 데이터(K개 그룹) 중 어디에 속하는지 분류하는 알고리즘

장점
- 직관적이고 단순함
- 학습 데이터에 존재하는 노이즈에 크게 영향을 받지 않음
- 학습 데이터가 많을 때 상당히 효과적이다
단점
- 어떤 K값이 좋은지 정하기 어려움 (하이퍼파라미터 튜닝 필요)
→ 데이터의 특성에 따라 임의로 선택해야 함
2) 서포트 벡터 머신(SVM) 알고리즘
데이터를 가장 잘 나누는 선(초평면)을 찾는다
두 카테고리 사이의 마진(여백)을 최대화하는 방향으로 데이터를 분류한다
SVM은 마진을 최대화하는 선을 찾아 분류하므로, 마진이 클수록 새로운 데이터가 들어와도 잘 분류될 가능성이 높다

마진 안에 있는 애매한 데이터는 ‘서포트 벡터와 얼마만큼 가까이 있는가’에 따라 분류한다
장점
- 사용하기 쉽고 예측력이 높다
- 복잡한 데이터도 잘 분류한다
단점
- 모델을 구축하는 데 시간이 걸린다
- 결과에 대한 설명력이 떨어진다
3) 의사결정 트리(Decision Tree) 알고리즘
데이터를 분류 규칙에 따라 트리 구조로 분류하는 분석 방법
질문을 따라 내려가면서 결정을 내린다
상위 노드에서 시작하여 분류 기준에 따라 하위 노드로 확장되는 방식이 '트리(나무)'와 닮았기 때문에 '의사결정 트리’라고 부른다

장점
- 직관적이고 분석 과정을 이해하기 쉬움
- 블랙박스가 아님 → 결과에 대한 명확한 설명이 필요한 경우에 유용하다
단점
- if-then을 형성하는데 개발자의 능력이 매우 중요하다
- 요새는 특징이 너무 많아져서 의사결정 트리를 잘 사용하지 않는다 (if-then이 너무 많아짐)
8. 군집화(Clustering) - 비지도학습
유사한 특성을 가진 데이터의 그룹인 '클러스터'를 형성하는 과정
데이터가 주어졌을 때 유사도에 따라 데이터를 클러스터로 분류한다
다양한 데이터가 섞여 있지만, 군집화 과정을 통해 유사한 데이터끼리 그룹화된다

1) K-평균 군집화(K-means clustering)
- K: 주어진 데이터를 그룹화할 그룹 수
- Means: 각 클러스터 중심과 데이터 간의 평균 거리
- centroid: 클러스터의 중심

과정 요약:
- K개의 중심점 초기 설정 (랜덤 선택)
- 각 데이터가 가장 가까운 중심점에 소속됨
- 중심점 재계산 → 반복
9. 강화 학습 알고리즘
에이전트(Agent)가 보상(reward)을 최대화하기 위해 학습한다
환경(Environment) 속에서 상태(State)를 보고 행동(Action)을 선택한다
1) 모델 기반 알고리즘(Model-based algorithms)
현재 상태에서 행동을 취했을 때 다음 상태로 전이될 확률을 참조한다
로봇이 격자 공간에서 상하좌우로 이동할 때 다음 상태를 직관적으로 볼 수 있다
모델 기반 알고리즘은 행동에 따른 상태 변화를 예측할 수 있어 최적의 해결책을 도출한다

10. 데이터셋 로드 및 용어
이전 포스트 참고하기
iris(붓꽃) 데이터를 이용해 품종 분류하기 (지도학습)
sklearn에 내장되어있는 iris 데이터셋을 가지고 간단한 지도학습을 해보자😋지금부터 이어질 실습은 윈도우 환경에서 Python 3.11.7 으로 진행했다!IDE는 VSCode를 사용했다 1. sklearn 설치pip install scikit
welcomekido.tistory.com
11. 성능 측정
이전 포스트 참고하기
교차 검증으로 숫자 필기 인식의 성능 측정해보기
이번엔 교차 검증(Cross-Validation)을 이용해 필기한 숫자의 인식 성능을 측정해보자😎우선 혼동 행렬, 훈련집합, 검증집합, 테스트집합에 대해 알아보겠다! 1. Performance Measurement (성능 측정)객관적
welcomekido.tistory.com
12. 머신러닝의 도전과제
1) 다양한 데이터 필요성 (Need for variety of data)
데이터에 따라 성능이 매우 달라진다
컴퓨터는 인간과 달리 0과 1만 인식할 수 있음
사람은 "자동차"를 사진으로 알아보지만, 컴퓨터는 숫자 배열로 처리함
→ 이 숫자를 적절히 해석하려면 많은 훈련과 데이터가 필요하다
2) 과적합 (Overfitting)
훈련 데이터를 과도하게 학습하여 실제 데이터 분석 시 성능이 저하되는 현상
모델이 훈련 데이터를 '너무 잘' 학습해서 훈련 데이터의 노이즈(잡음)까지 학습하는 현상
= 마치 시험에 나올 문제들을 그대로 외워서 시험은 잘 보지만, 실제 응용 문제는 풀지 못하는 상황과 비슷하다
학습 데이터에 너무 딱 맞게 학습됨 → 실제 새로운 데이터엔 성능이 낮음
이는 문제의 복잡성에 비해 데이터가 크게 부족할 때 발생한다
즉, 학습 데이터가 문제가 정의된 전체 공간을 커버하지 못하고 일부 케이스에만 집중할 때 발생한다

(a) 일부 구간만 잘 맞고 전체적으로는 엉망 (과소적합(Underfitting))
(b) 전체 흐름 잘 반영 (최적합(Optimal))
(c) 학습 데이터에 너무 잘 맞음 (과적합(Overfitting) →새로운 데이터엔 안 맞을 위험
(b) 그래프보다 (c) 그래프가 더 좋은 그래프일까?
모든 데이터 포인트를 정확히 지나는 모델(c)이 데이터의 일반적인 경향성만 반영하는 모델(b)보다 더 나은지에 대한 의문
→ 이에 답하기 위해서는 실제 데이터 값으로 테스트해봐야 한다

실제 데이터(테스트 데이터)를 사용해 세 모델을 평가했을 때, (b) 그래프의 모델이 가장 작은 오차를 보이므로 최적합(Optimal) 모델이라고 할 수 있다
→ 학습 데이터에 완벽하게 맞는 모델(c)이 실제로는 새로운 데이터에 대해 더 나쁜 성능을 보일 수 있다
머신러닝에서는 모델이 훈련 데이터에 너무 맞춰지지 않도록(과적합) 하면서도, 데이터의 중요한 패턴은 포착할 수 있도록(과소적합 방지) 균형을 맞추는 것이 중요하다
과적합 방지 방법:
- 더 많은 훈련 데이터 사용
- 모델의 복잡도 줄이기 (예: 더 단순한 모델 사용)
- 정규화(Regularization) 기법 사용
- 드롭아웃(Dropout)과 같은 기법 사용 (주로 딥러닝에서)
13. PyTorch
파이썬 기반의 과학 연산 라이브러리이자 딥러닝 프레임워크
- 사용법이 직관적
- 디버깅이 쉬움 (코드 흐름이 일반 파이썬 코드처럼 직관적)
- GPU 가속 지원
- 연구자/개발자 모두에게 인기 많음
동적 계산 그래프(Dynamic Computation Graph)를 사용하여 더 파이썬스러운(Pythonic) 코딩 스타일을 제공한다 → 코드를 실행하면서 계산 그래프가 실시간으로 구성된다
PyTorch를 이용한 MNIST 이미지 분류
CNN(Convolutional Neural Network) 아키텍처를 이용한 시각 인식(visual recognition) 구현

딥러닝 모델(CNN)을 사용한 이미지 분류 모델의 전체 개발 흐름을 보여주는 순서도 (PyTorch를 사용할 때의 전형적인 단계가 모두 포함되어 있음)
이 흐름도는 다음과 같은 큰 세 단계로 나눌 수 있음
- 데이터 전처리 단계
- 모델 학습 단계
- 예측 및 테스트 단계
1) Start → Load the Dataset (데이터 불러오기)
학습에 사용할 이미지 데이터셋을 로드 일반적으로 PyTorch에서는 `torchvision.datasets` 모듈을 통해 데이터를 쉽게 불러올 수 있음
2) Read the Dataset (데이터 읽기)
데이터셋의 구조를 파악하고 각 이미지가 어떤 레이블을 가지는지 확인하는 과정
3) Normalize Test Dataset using torchvision (정규화) → 필요할 때만 함
이미지 데이터의 범위를 바꿔주는 과정
신경망은 큰 수보다 작은 수(0~1 범위)로 정규화된 입력에서 더 안정적으로 작동
4) Define Convolution Neural Network (CNN 정의)
합성곱 신경망을 설계하는 단계
CNN은 이미지 분류에 매우 효과적인 구조로, 보통 다음처럼 구성됨:
: Conv2D layer → ReLU → Pooling → (반복) → Fully Connected Layer
5) Define Loss Function (손실 함수 정의)
예측값과 실제값의 차이를 수치로 나타내는 함수
손실 함수와 최적화 알고리즘을 정의
6) Train the Network (네트워크 학습)
입력 데이터를 모델에 넣고 출력값을 얻은 후,
- 손실(loss)을 계산하고
- 그라디언트를 통해 가중치를 업데이트하는 역전파(backpropagation) 수행
이 과정을 반복해서 모델이 점점 더 정답을 잘 맞추게 만듦
반복) Repeat the process to Decrease the Loss
에폭(Epoch): 데이터 전체를 몇 번 반복해서 학습할 지를 정함
학습을 여러 번 반복하며 loss가 줄어드는 것을 확인

validation 값을 가지고 w, b를 조절한다
Loss는 0으로 수렴하는 형태로 가야한다
7) Test the Network Based on Trained Data (학습 데이터로 테스트)
Validation 데이터셋으로 성능 확인
학습한 모델이 학습 데이터에 대해 얼마나 잘 예측하는지 확인
보통은 훈련 정확도(Train Accuracy)로 확인
8) Make Prediction on the Test Data (테스트 데이터로 예측)
Test 데이터셋으로 성능 확인
학습에 사용되지 않았던 데이터로 일반화 성능 평가
14. TensorFlow
딥러닝에서 데이터를 표현하는 표준적인 방법
구글에서 만든 딥러닝 프레임워크
핵심 개념: Tensor(다차원 배열) + Flow(데이터 흐름) = 데이터 흐름 그래프 기반 연산

전통적으로 정적 계산 그래프(Static Computation Graph)를 사용했으나, TensorFlow 2.0부터는 즉시 실행(Eager Execution) 모드를 기본으로 채택하여 PyTorch와 비슷해짐
- 생산 환경 배포에 강함 (서버, 모바일 등) → 산업계에서 널리 사용
- 다양한 언어 지원 (파이썬, C++, JavaScript)
- 시각화 툴(TensorBoard) 제공
